Object Detection based on Region Decomposition and Assembly
AAAI2019 | 基于区域分解集成的目标检测 论文解读

作者 | 文永亮
学校 | 哈尔滨工业大学(深圳)
研究方向 | 目标检测、GAN
推荐理由:
这是一篇发表于AAAI2019的paper,文章提出了一种R-DAD的方法来对RCNN系列的目标检测方法进行改进。
研究动机:
目前主流的目标检测算法分为1 stage和2 stage的,而2 stage的目标检测方法以Faster-RCNN为代表是需要RPN(Region Proposals Network)生成RoI(Region of Interests感兴趣区域)的,文章认为正是因为被遮挡了的或者不精确的Region Proposals导致目标检测算法的不准确。作者的想法动机其实很简单,就是假如一辆车的左边被人遮挡了,那么这辆车的右边带来的信息其实才是更可信的。基于这个想法,文章提出R-DAD(Region Decomposition and Assembly Detector),即区域分解组装检测器,来改善生成的Region Proposals。
R-DAD的网络结构:
文章以Faster-RCNN的网络结构为例,修改成它提出的R-DAD结构:
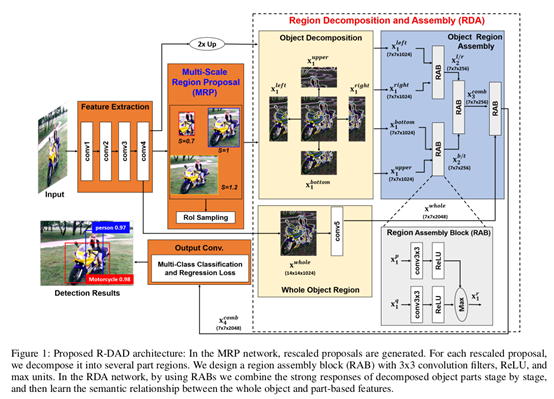
R-DAD网络架构主要分成两个模块MRP和RDA:
- MRP(Multi-Scale Region Proposal)模块,用来改善RPN生成的Region Proposals的准确率。

图一:MRP模块,框内分别对应S=0.7,1,1.2的Region Proposals
MRP表面意思就是生成多尺度的Region Proposal,方法很简单,就是使用传统的RPN生成一些建议框,然后用不同的缩放因子(文章使用了5种缩放因子作为一组s=[0.5,0.7,1,1.2,1.5])对生成出的建议框进行不同比例的缩小放大从而提高Region Proposals的多样性。如图一,生成了不同尺度的区域,有一些仅仅是局部有一些是大于目标本身的,但是这也带来了一个问题,就是原来的Region Proposals已经可以说是极大的数量了,再乘以五倍,想要网络能够完全利用这些建议框是不切实际的,作者最后还添加了RoI的采样层,对分数低的和跟ground truth重叠率低的进行了筛选。
由MRP网络生成的各种Region Proposals可以进一步适应目标之间因为空间变化所导致的特征变化,提高结构的鲁棒性。
- RDA(Region Decomposition and Assembly)模块,作者也称它为mutil-region-based appearance model,即基于多区域的外观模型,它可以同时描述一个物体的全局外观和局部外观,RDA分为目标分解和目标区域集成的两部分,目标分解如图二所示,把一个目标分为上下左右四个方向的分解部分

一般会先用线性插值两倍上采样之后再分解,后面作者给出了表格表示这样效果更好。左右刚好是特征图的左右一半,上下也同理,都会送入RAB模块,RAB模块如图三所示:
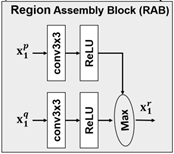
图三:RAB模块
其实就是下面这个函数:
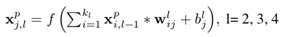
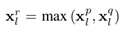
其中p代表着上下左右的每一个部分或者组合后的部分如左-右(l/r)、下-上(b/u)和comb(l/r与b/u的组合),*是卷积操作,f()是ReLU单元。最后再取max,是为了融合了
 和
和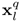 的信息,生成同样大小的
的信息,生成同样大小的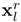 。最后
。最后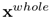 就是代表着全局信息的scale为1生成的Region Proposals,一起送进RAB模块。这样整个网络结构就可以做到既捕捉到局部信息的同时,也不丢失全局信息。
就是代表着全局信息的scale为1生成的Region Proposals,一起送进RAB模块。这样整个网络结构就可以做到既捕捉到局部信息的同时,也不丢失全局信息。RAB模块是一个类似maxout的单元,理论上它可以逼近任何连续的函数,所以我们使用RAB而不是直接使用ReLU。这表明可以通过配置不同的分层地组合RAB模块来表示各种各样的目标特征。
损失函数:
对每一个框(box)d,我们都会通过IoU筛选出跟GT(ground truth)最匹配的d*,如果d跟任何的d*的IoU超过0.5,给予正标签
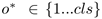 ,若在0.1到0.5之间的,给予负标签。R-DAD的输出层对每一个框d都有四个参数化坐标和一个分类标签
,若在0.1到0.5之间的,给予负标签。R-DAD的输出层对每一个框d都有四个参数化坐标和一个分类标签 。对于box regression来说,我们与以往目标检测的参数化一致如下:
。对于box regression来说,我们与以往目标检测的参数化一致如下:
同理,
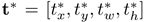 是用来评估预测框和GT的差距的。
是用来评估预测框和GT的差距的。跟训练RPN网络相似,R-DAD也需要最小化分类损失和回归损失,如下:
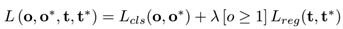

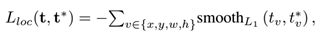
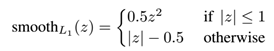
实验结果:
文章中做了各种设置的组合,关于MRP里缩放因子的组合、是否有RDA模块以及是否上采样,得分如下表所示:

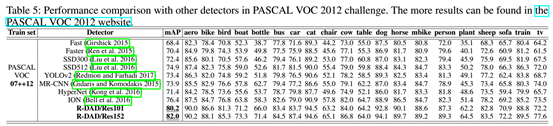
与Faster-RCNN对比,作者使用了VOC07trainval和VOC12trainval数据集训练,再在VOC07test上测试,并且用了不同的特征提取器(VGG、ZF、Res101),得分均比Faster-RCNN高。
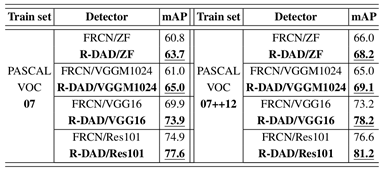
在速度方面均比Faster-RCNN慢。

与没有上下区域分解集成的R-DAD对比,有上下分解集成的误判率低很多,因为它在复杂情形下被遮挡物体会更有选择地相信得到的信息。

R-DAD的优点:
1.文章提出因为我们最大化目标在横向空间位置上局部特征的语义响应,与使用支持小区域的最大池化相比,在没有深层次结构的情况下,我们可以改善特征位置的空间不变性。我的理解就是作者取了上下左右四个方向的特征模板,最后对四个方向进行了融合语义信息,利用了横向空间上的空间不变性,揭示了不同方向上的语义关系。
2.在复杂场景下,如有目标对象被另一目标对象遮挡时,通过左右上下模板筛选出来的特征是更符合真实场景的,这样的Region Proposals也更加可信。
3.同时描述了全局特征和局部特征的语义信息,在RAB的组装上具有很强的可操作性,通过配置分层式地组装RAB模块,以及修改特征模板,特征的表达会更加灵活。
点评:
这个区域分解集成的算法令我觉得跟以前传统的人脸识别算法提取Haar-like特征有点异曲同工之处,同样都是把特征图分成上下两部分,然后做特征提取操作,都是定义了特定的特征模板,这就很容易理解为什么作者要做multi scale的操作了,因为在以前使用Haar/SIFT/HoG的时候,往往都需要使用muti scale来检测。
但是R-DAD为什么对特征只分成上下各一半,左右各一半这种特征模板,文章并没有给出令人信服的理由。尽管如此,这也是一个对目标检测的改进方向,通过MRP和RDA模块代替了之前的单纯的RPN网络,而且在不使用FPN(Feature Pyramid Networks)的情况下取得了不错的mAP,这样看来R-DAD是2 stage目标检测系列的另一种技巧,综合了横向空间上的语义信息。